The Next 1000x Cost Saving of LLM
LLM inference costs have dropped a lot over the past three years. At a comparable quality to early ChatGPT, average per-token prices are ~1000x lower, as observed in an a16z blog. That drop has been driven by advances across the stack: better GPUs, quantization, software optimizations, better models and training methods, and open-source competition driving down profit margins.
While many of the existing LLM optimizations look like low-hanging fruits, people may doubt that costs will keep dropping so fast, just like the long-running doubts about Moore’s law. The good thing is that it’s easier to predict cost trends than to predict the intelligence trends of LLMs.
In this article, I argue that we’ll see another 1000x cost reduction in LLM applications over the next 3 years. But the metrics will shift - not just by “input tokens” and “output tokens.” Token-based pricing will persist, yet the economic model must evolve to capture the emerging needs.
When we look at an optimization problem on a 3‑year horizon, everything changes: the models, the systems, and how people use them. LLM workloads will not scale in a simple, proportional way. The cost of today’s workloads is hard to fall by 1000x; however, if you take the dominant workload 3 years from now, you may find it is 1000x more expensive on today’s stack.
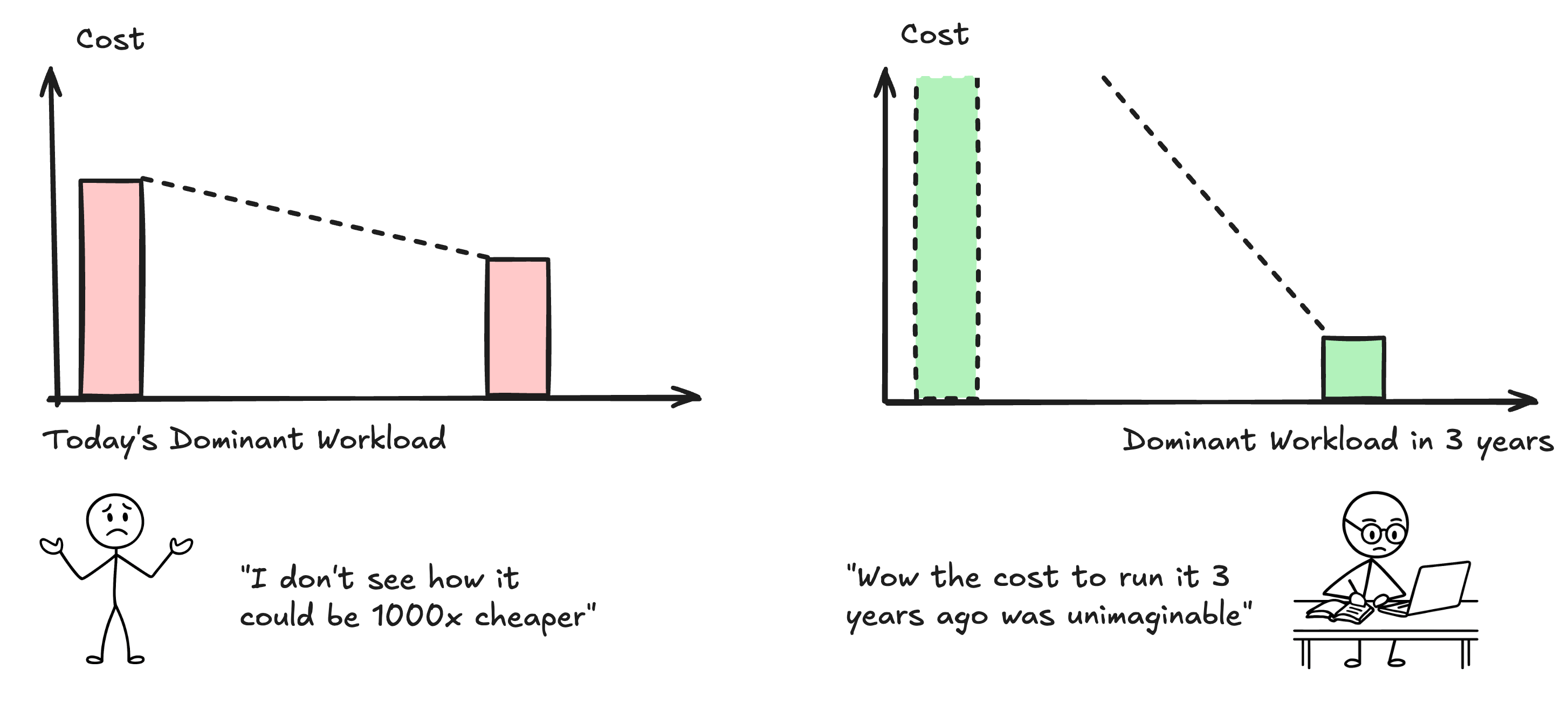
In 2024, it was estimated that even if all 8 billion people on Earth talked to a chatbot for 20 minutes daily, the usage would only consume on the order of half of NVIDIA’s 2024 GPU production. In 2025, we are witnessing reasoning models and coding agents becoming much more greedy token consumers than chatbots. It is still quite expensive to run an agent for minutes-long tasks. Compared to chatbots, agents don’t merely consume more tokens—they exhibit fundamentally different workload patterns, and they will keep evolving in the next 3 years.
Predict the shift of workload patterns
Trend 1: longer context and horizon. Longer context means not only more tokens but also higher cost per token; see, for example, the DeepSeek per-token cost curve.
Longer horizon, on the other hand, means more steps and longer runtimes.
- From an API perspective, cached tokens incur costs that grow quadratically with the number of steps, as illustrated in the following figure. Cache reads already account for more than half of the overall cost of coding tools like Cursor or Claude, one example reported in this post.
- From a systems perspective, cached tokens are just KV cache. Keeping KV cache alive for longer implies a higher memory-to-compute ratio for the serving system.

Over the next 3 years, we may witness an evolution from single-task agentic LLMs to always-on, long-lived agents, which will put much greater stress on current systems. Anthropic is among the first to emphasize long-running capabilities in their models and to support a 1-hour cache lifespan in their API.
Trend 2: wider execution paths, represented by asynchronous tool calling, parallel thinking, specialized models, or asynchronous self-calling.
Allowing an LLM to perform multiple tasks concurrently and scale out its “thinking” can significantly enhance capability while reducing time-to-result. This will make a purely token-based pricing model harder to sustain in the long term. Agent providers like Manus have already recognized this and price in “credits” instead of tokens, to better reflect total compute cost.
Speculation: more customization. There has been a constant debate of generalists vs. specialists. Today, customization for specialist LLMs is mostly achieved through context engineering, while we see some limited demand met through finetuning services provided by OpenAI, Thinking Machines Lab, and others. I predict that stronger customization beyond context engineering will be needed for environment adaptation and collective intelligence. This demands both system support for efficient hosting and algorithm improvements to address issues like catastrophic forgetting.
Forecast the next 1000x
Now the question becomes: if we focus on the dominant workload pattern expected in 3 years rather than today’s prevalent workloads, where will the major cost savings come from? Let’s first establish today’s baseline:
- Hardware: 8×B200 HGX system, with each GPU providing 192GB HBM3e memory and 4.5 PFLOPS. While the GB200 NVL72 system offers higher upper bounds, it remains less mature and less widely available across cloud providers.
- Inference software: DeepSeek V3/R1 inference system, which features FP8, Wide-EP, and PD disaggregated serving. Despite being released nearly a year ago, DeepSeek’s software efficiency—with ~35% MFU for prefill and ~15% MFU for decode—still outperforms many US model providers.
- Application software: coding agents like Cursor and Claude Code, which still largely rely on manual context engineering and simple heuristics for agent memory management.
I made some bold predictions of improvements over the next 3 years:
| Source of improvements | Improvement measured by today’s applications |
Improvement measured by future applications |
|---|---|---|
| Memory technology | 2x | 2x |
| Process node & microarchitecture (on top of memory improvement) |
1.25x | 2x |
| Heterogeneous system scaling | 2.5x | 5x |
| Model & algorithm | 4x | 10x |
| Agent scaffold | 4x | 10x |
Memory capacity and bandwidth are currently the biggest bottlenecks in LLM serving systems. Among all memory types, HBM is the most important and is projected to advance two generations (HBM3e → HBM4 → HBM4e) in 3 years, bringing roughly a 2x bandwidth and capacity improvement.
Semiconductor process node & microarchitecture improvements, measured by FLOPS, will likely outpace memory improvements. However, most of today’s workloads are memory-bound, so increased FLOPS would not help significantly (estimated as 1.25x). Future applications with wider execution paths and hardware-friendly model design will better harvest the architectural gains.
Heterogeneous system scaling refers to scaling inference serving systems through specialized chips and diverse node configurations. One example is Rubin CPX, a prefill-optimized GPU that can replace high-end HBM GPUs at lower cost. Beyond prefill specialization, future applications will unlock more opportunities for purpose-built chips and tailored system configurations.
Some may wonder where compilers and inference software fit in this table. They are embedded in microarchitecture and heterogeneous systems to avoid double counting. New architectures will be harder to optimize with the current compiler stack and demand significant innovation to maintain utilization. Likewise, larger heterogeneous clusters will require substantial software work for orchestration.
Model & algorithm innovations have historically contributed the most to cost reduction ever since the CNN era.
- Better data quality and smarter training methods will continue to boost model capability and thus reduce effective cost. Recent examples are on-policy distillation and length-optimized RL training.
- Efficient model architectures, e.g. sparse attention, will reduce cost modestly for today’s workloads and dramatically for future long-context, long-horizon applications.
- On quantization, many providers nowadays serve models in 8-bit formats, while some with inferior capability still run bf16. 4-bit formats such as NVFP4 and MXFP4 (also see my previous quantization blog) are likely to be widely deployed within 3 years.
Overall, I’m comfortable predicting at least a 10x gain from models and algorithms alone.
Agent and its scaffold is an emerging area driven by application needs. It designs how the LLM interacts with the environment, other LLMs, and itself.
- Interface is critical. While researchers train models to better operate on real-world APIs, developers are also learning that not all interfaces are equally effective or token-efficient for LLMs. Anthropic’s recent blog shows that changing the interface can reduce token usage by 98.7%.
- Memory management, specifically, managing short-term memory (LLM context) and persistent memories (episodic memory, semantic memory, etc), is another important lever. Efficient memory management like Mem0 could make a huge difference in agent capability and cost.
- Multi-agent system with specialization could further boost efficiency. Aider is one of the first agent implementation to support separate roles such as architect/coder.
There are many opportunities in this space, and it is not surprising to see another 10x cost reduction out of this layer.
Summary – combining the optimizations above, we arrive at an estimated ~2000x efficiency improvement. On the other hand, the cost of HBM modules and leading-edge chip area will likely increase by 1.5–2x, depending on manufacturing costs and demand.
Final words
Good optimizations cut today’s costs. Great optimizations unlock tomorrow’s needs.