Codex as an assistant - the power and pitfalls
Over the past three months, every time I felt ready to write about coding agents and personal assistants, something new came out and my views needed updating. Things are changing constantly. Any practical guide in this space may be outdated in 3–6 months, so I want to write down my thoughts on more fundamental problems.
Since the start of this year, I have been trying OpenClaw and other variants. They are great personal assistants for daily tasks, but they often fail at complex, multi-step functionality. On the other hand, coding agents like Claude Code and Codex are strong at implementation and execution, but they lack cross-session memory and persistent context. What I really want is a personal assistant that can implement code reliably, remember what it did, and freely switch between projects. So I built one.
Coding agents as assistants
SeedBot is built on two beliefs:
-
Coding is the core capability for procedural tasks and self-improvement. File operations, API calls, web automation, data analysis—they all reduce to code execution. A personal assistant that can write and run code is fundamentally more capable than one that relies on pre-built integrations. Moreover, the assistant should be able to reliably overwrite itself to add new capabilities.
-
Leverage, not compete. Coding agents are improving at a staggering pace. Rather than building a custom LLM pipeline from scratch, SeedBot rides on top of existing agents like Codex, inheriting their improvements for free. The goal is to add the missing layers—persistence, memory, extensibility—without reinventing what already works. SeedBot was barely usable with Codex 5.2, but it suddenly became helpful with the new Codex harness and the release of Codex 5.3.
Design
It is actually suprisingly simple to turn Codex into a ever-evolving personal assistant. SeedBot has only two overwritable modules plus file-based memory, all under 100 lines of Bash:
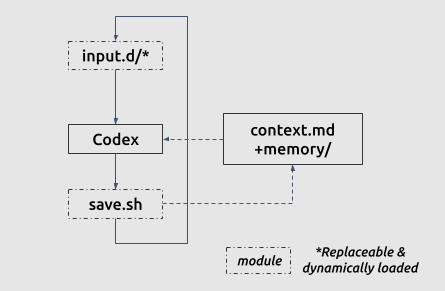
- Input hooks - inputs.d/: How the agent receives tasks: Slack messages, scheduled triggers, file watchers, or direct CLI invocations.
- Callback hook - save.sh: How the agent reports results: posting to Slack, writing to a log, sending notifications, or updating a dashboard.
- File-based Memory: Persistent storage of past interactions, project context, and learned patterns that carry across sessions.
The key design choice is that all three entrypoints can be modified by the coding agent itself. If SeedBot needs a new input channel, it can write one. If it needs a new callback format, it can implement it. This provides extensibility without me having to anticipate every use case upfront.
What SeedBot does
From this simple design, SeedBot can do virtually anything: daily digests, reproducing papers, and launching jobs on GPU clusters. I also asked it to implement its own Slack interface for better communication, which I put on GitHub as a reference. Below is a snapshot of how I work with SeedBot:

I’ve tried OpenClaw, NanoClaw, and NanoBot, but so far SeedBot with my preferred interface works best for my daily workflow. That said, this post focuses more on my general findings of working with agents.
Limitations of coding assistants
This is an era when everyone can build their own customized assistant in half a day. I want to talk about something more fundamental:
If coding an agent and letting agents code are so cheap now, what are the remaining bottlenecks?
Cost of verification
The overall productivity boost can be described as:
\[\text{productivity boost} = \frac{1}{\frac{1}{\text{generation boost}} + \frac{1}{\text{verification boost}}}\]So far, the cost of verification is dropping more slowly than the cost of generation, which limits the overall productivity boost. Verification includes many different things, from plain functional testing to high-level understanding and steering of agent behavior. I encountered two main types of verification work:
Functional testing. It is easy to ask agents to come up with unit tests, but hard to know whether they are actually testing what you want. Well-defined tasks like environment setup, codebase migration, experiment reproduction, and clearly defined feature requests work well because success is easy to check. Open-ended tasks like “increase accuracy on this benchmark” or “improve the user experience” are much harder, because the agent cannot tell when it is done.
Given SeedBot’s goal of “self-evolving,” it is hard to come up with standard unit tests. Subtle changes in working style or conversation tone are difficult to adjust without human-in-the-loop evaluation. Most of my development time went into manually testing edge cases and iterating on prompts, which feels more like tuning a system than engineering one.
Understanding and steering. This is a more fundamental problem when working with agents. Do you truly understand what your agent is doing? How do you control your agent without reading every line of code?
I have been programming for almost 20 years, and the sense of not knowing what is going on under the hood is unsettling. So I have been thinking about how to increase productivity while still maintaining confidence in the system’s behavior, including:
-
Let a different agent review. Cross-checking with a separate agent instance catches a surprising number of issues. But this has limits—see below.
-
Ask the agent to stay organized and maintain a summary. Have the agent maintain documentation for itself: what it has done, what assumptions it made, what it left unfinished. This works surprisingly well, and greatly improves the agent’s own consistency.
-
Think in anchors. As engineers, we are used to scoping tasks by amount of work. But as an “agent manager,” we should scope tasks by verifiability. The key is to find verifiable interfaces that require as little context as possible to check. Think about unit tests, which aim to test minimal functionality—but instead of looking for minimal functionality to test, think about artifacts that do not need full context to verify. A well-defined API contract, a passing test suite, a reproducible benchmark result—these are good anchors. “The code looks right” is not.
Cost of maintenance
Why am I so obsessed with reducing lines of code and functionality, while many people proudly announce that they have written hundreds of thousands of lines with coding agents? My observation is that the maintenance cost, i.e., the cost of adding or modifying something, roughly scales with the size of the existing codebase:
\[\text{Cost of a feature} = \text{Feature code} \times \text{Cost of understanding existing code}\]The cost of understanding existing projects ranges from $O(n)$ (extremely ill-designed) to $O(\log n)$ (extremely well-designed), where $n$ is the number of lines of code. This applies to both humans and agents. While coding agents lower the maintenance cost of existing projects, agent-era projects will grow to astounding complexity at an astounding pace (think OpenClaw’s 1M lines of code), making maintenance costs significant again.
My experience with SeedBot is that coding models are far better at adding code than removing it. They prefer adding a new if block over generalizing an existing branch, and resist deleting working code unless you are extremely explicit. When I asked Codex to merge two overlapping subsystems (memory saving and callbacks), it took several rounds of increasingly specific prompts before it would comply—even though the merged version was strictly better. There is a deep conservatism baked into these models: if existing code works, they avoid the risk of breaking it, even at the cost of long-term maintenance debt.
Coding is becoming cheaper. This has a counterintuitive implication:
Code is increasingly becoming a liability rather than an asset. The more code you have, the more you need to maintain, test, and understand. So what would be the true value of a software project?
-
Interfaces. Well-designed code-to-code and code-to-human interfaces eliminate the need to understand many components. Needless to say, widely adopted interfaces have real capital value.
-
Design elegance. Inside the codebase, elegant code greatly reduces the cost of understanding a component, making long-term maintenance sustainable.
So far, elegance in LLM-generated code is still largely lacking, probably because it is difficult to define a loss function or an RL reward for elegance. But I believe the human appreciation of elegance must have survival value; otherwise it would not exist in almost every individual today. Elegant code is not only easier for humans to comprehend, but also easier for coding agents to maintain and safer to expand.
Side thoughts
What else limits getting things done?
An assistant is a level above a coding agent. Coding agents increase the velocity of individual implementations; assistants increase the velocity of every procedural task. But in my experience, several fundamental bottlenecks remain:
Compute. The agent can launch training runs, configure inference experiments, and monitor them for me. But training is ultimately bottlenecked by GPU availability. That same limitation also applies to anything limited by the physical world.
Ideas. So far my agents have not been very successful at generating great ideas, including new research directions or fixes for new problems. SeedBot can execute a well-defined plan efficiently, but it cannot tell me what to work on next. The ideation step remains firmly human.
Long-term consistency and self-improvement. As a project grows, the likelihood of misremembering increases, and the cost of verification increases with it. Humans are good at creating abstractions to keep track of things and iterating on self-understanding. Agents, however, are not yet very good at this. Efforts like skill evolution are not sufficient.
Claude Code vs. Codex as personal assistants
For SeedBot, it is just one line of change to replace Codex with Claude Code, and here are my observations:
Claude Code with Opus 4.6 feels more human-like. It is willing to wait for slow operations, shows patience with ambiguous instructions, and produces conversational outputs. But it is also more likely to make mistakes—misinterpreting a directory structure, or confidently executing the wrong command without double-checking.
Codex with GPT 5.4 has better situational awareness. It is careful, methodical, and reports every detail of what it is doing. It checks preconditions before acting and flags potential issues rather than silently proceeding.
Note: GPT 5.5 just came out. I found it to be the perfect model for personal assistant use: well organized and direct. Give it a try!
As a personal assistant with direct machine access, I found Codex to be the more reliable choice. When the agent can rm -rf your files or push files to a public GitHub repo, I want careful over creative, so Codex is my default choice.
Final words
This post is meant to share my thoughts and findings from building SeedBot. I do not expect SeedBot to be widely adopted—that was never the point. The point is that everyone can build their own personal assistant by building on top of coding agents.
When I was studying English at school, I was told that to reach the reading speed of native speakers, I needed to stop the habit of subvocalizing every single word. Now we are facing a similar situation: to fully empower ourselves, we need ways to understand and control agents at a higher level than manually reviewing everything. Some may say this is just like being a people manager, but I disagree, because employees have accountability and agents do not. I am sure people will come up with innovative ways to work with agents.